データベース設計の要点は、『One Fact in One Place:1つの事実は1つの場所にのみ存在する』 という点。 自分なりの理解としては、「ある具体的なデータは、データベース内で重複して持たない」ということだと思った。
プログラミングにおいても『DRY原則 【Don't Repeat Yourself】』があるように、データベースの世界においても同様のことが大事ということ。
それを実現するための指針となっているのが、正規化という手法で、『データベースのデータ構造を部品化』し、『One Fact in One Place』となるデータベースを設計する際に用いられる。
ちなみに『One Fact in One Place』の旨味は、管理がしやすいという点であると思った。例えば、データ更新があったときに当該データの更新だけで済む。一方、複数箇所に修正すべきデータがあると、全て更新しないといけないし、更新タイミングがずれると、変なデータが表示されてしまう。割とデータベース設計とプログラミングは通じるところがあるんだなと感じました😅。
手順の概要を下記のような伝票データに対して簡単にまとめる。
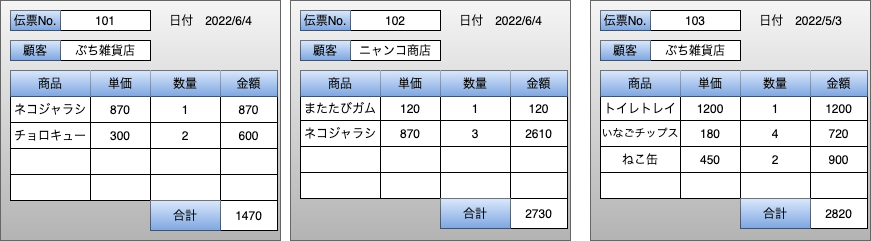
IDの導入
IDの導入のイメージは、重複を避けるために特に意味を持たない『ID』という属性を各テーブルに持たせ、IDによりデータ参照をさせるというもの。各テーブルの関係をIDの参照にすることで、『One Fact in One Place』に近づけることができる。プログラミングでいうところのポインタの考えに近いと思う。
具体的な実施を上記のテーブルに対してやってみる。まず、帳票のレイアウトに沿って、全部のデータを書き出してみる。その後、重複であったり、各データの組み合わせで計算できるもの(金額や合計)を排除して、正規化を進める。最終的に作られるテーブルとERD図は次のようなものになる。
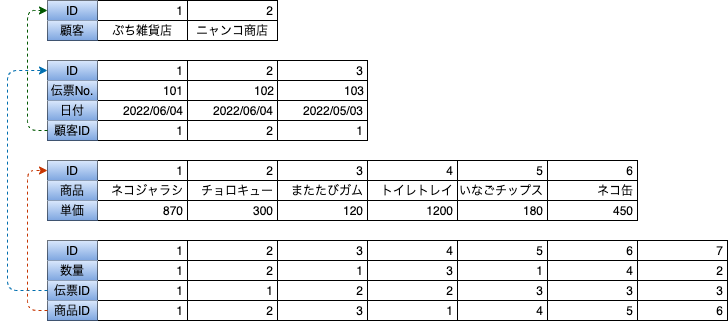
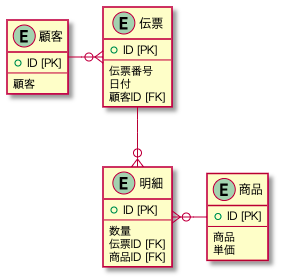
上記のように、IDが主キーの役割を担っているが、IDは外部参照キー(FK)として各レコードへのポインタの役割をしているだけで、実際のデータというわけではない。よって、参照先のテーブルに何かしら変化があったとしても、現状の参照構造には変化がないため影響を受けない。
業務視点からの正規化
伝票データだけを考慮するだけで十分かというとそうではない。例えば、お得意様や大量注文の場合には値引きなどがある。つまり『単価は決まっているけど、発注の状況によって金額が変わる』ということ。そういった状況だと、上記で示したERDは正しくないため、下記のようにする必要がある。
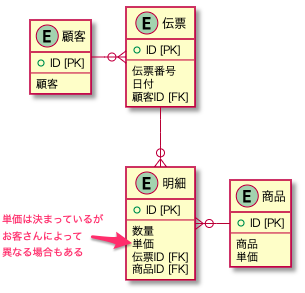
上図だと、正規化が不十分という印象があるが、ここを分けておかないと当該の状況をプログラムで判断する際に、結局は見分けるための区分が導入され、プログラムもそれに対する条件文を追加するなどして、ロジックが複雑になりやすい。よって、『必ず同一要素は単一にするというのが正規化の全てではなく、業務視点も考慮した上で正規化する』ということが重要。
データベース設計における3つのポイント
データベース設計の悩み事は、次の3つに分類されるらしい。
- 箱(エンティティ)の見出し方
- 主キーの設定
- 重複の削除(いわゆる正規化)
箱(エンティティ)の見い出し方
エンティティとは、『何かの集合』という意味らしい。あるモノが、その集合の中に属すかどうかを明確に区別できる、箱(エンティティ)のようなものだと考えるとイメージしやすい。
よって、エンティティは『何かの集合』であるため、それを表現するビッタリの名前が存在するはず。それがエンティティ名になる。
エンティティはデータベースの中で構成するので、エンティティ名自体もデータベースで『何を記録したいのか』ということが名前の候補になる。
また、エンティティの分類として、『イベント系エンティティ(出来事の記録)』と『リソース系エンティティ(モノの記録)』がある。エンティティ名を見出す際には、この分類をベースに、6W3Hの切り口で見出していくと良いらしい。
イベント系
動詞で表現できるものがイベント系。例えば、『注文する』とか『予約する』とか。
エンティティの候補 6W3H どのように(販売・仕入・出荷・入金など) How リソース系
名詞で表現できるものがリソース系。例えば、『商品』とか『部品』とか。
エンティティの候補 6W3H 誰に(顧客・仕入れ先など) Whom 誰が(従業員・役職・組織など) Who 何を(商品・勘定項目など) What どこ(販売ルート・地域・支店、営業所など) Where 属性の候補
リソース系やイベント系を修飾するようなもの?😅イメージ的には、単価とか期間とか。
エンティティの候補 6W3H いつ When どれくらい(量) How many いくら(金額) How much ビジネス上の正規化対象となるもの
ビジネス上『別の事実』となるもの。例えば、ある商品の単価があっても、お得意様には値引きするような場合、そうした事実を記録する。
エンティティの候補 6W3H なぜ(売上・返品・値引き・補充など) Why
上記のようにして、エンティティ名を洗い出していくと、データベースモデルとビジネスが「合致しているか?」や、「抜け漏れはないか?」などを検証できる。
主キーの設定
主キーの役目は、次のようなもの。
- 候補キーの中から何らかの意味的に選択された、インスタンスを特定可能な識別つし
- 物理的にPRIMARY KEY(制約)
NOT NULLのユニークインデックス
こうみると、何かしらの事実を識別できる形にできるのであれば、主キーは何でも良いと言える。そこで推奨されているのが、ID(アイデンティファイア)を主キーとし、IDをポインタのようにして参照することで、レコードを特定するというもの。
重複の削除
正規化は、『最小限のデータで必要十分なアウトプットを組み立てられる』ようにするというもの。この観点を満たすように、重複を削除していく。この観点だと、上にも書いたような値引きなどは、商品の単価からも止まるようなものでないため、記録用に残す必要があるということにも納得できる🧐 前述したように、ビジネス上『別の事実』となるようなものは、重複ではないため削除してはいけない。
データベースの設計手順
大まかには下記のような手順。
大まかにブロック分けを行う
部門で分けるなら営業・購買・生産など、業務でわけるなら販売管理・生産管理など。ユースケースに分けた切り分けもOK。
ブロックごとにイベント系を洗い出す
なすすべきこと(目的)は何なのかを考える。基本的には動詞で言えるようなもの。ここでのポイントは正規化を考えないで、ざっくりと大きなエンティティを書き出す。
イベント系エンティティの正規化
正規化してみて、エンティティの妥当性を確認する。これを実施することで、リソース系の候補が浮かび上がってくるので、リソース系エンティティも洗い出していく。
リソース系エンティティの分類を整理
副集合(部分集合+部分集合=集合全体となるような集合の一部分)は、エンティティ化してしまう。
ブロック間でリソース統合
イベント系はブロックごとに独立しているが、リソース系は重複していることが多いため、ブロック間でリソース系エンティティの統合を進める。
導出系の整理
複数のエンティティを組みあせて導出するものは、ビュー(仮想表)で表現できるので、冗長なものとして排除する。