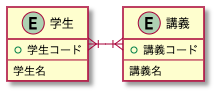
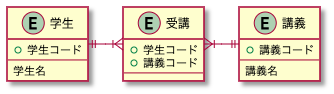
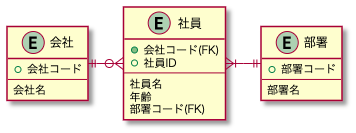
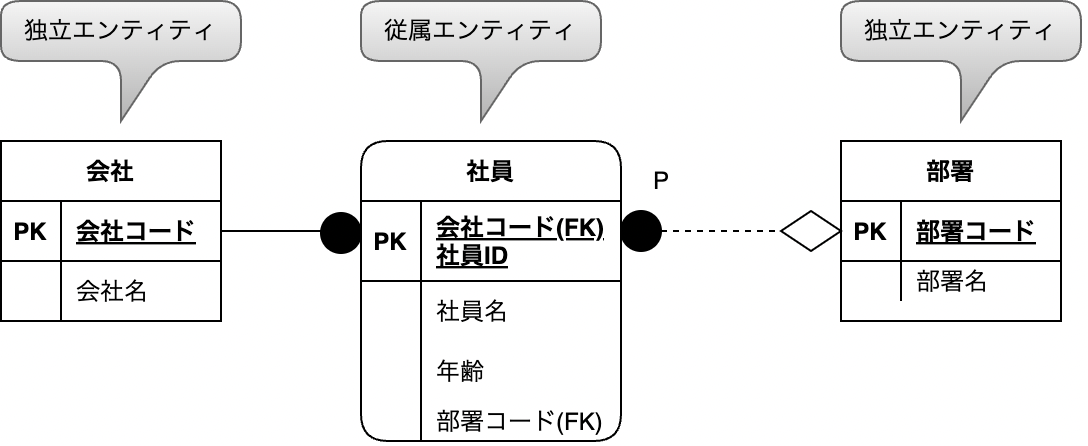
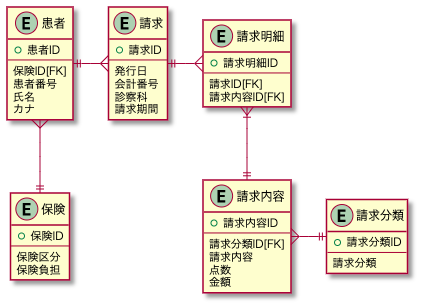
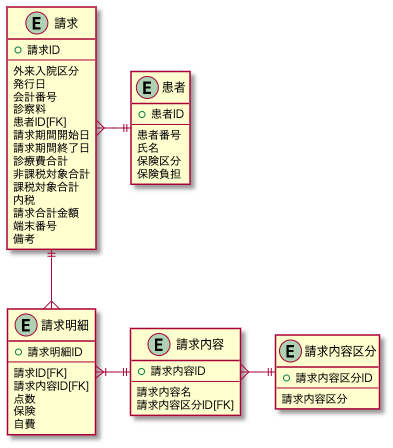
表とテーブルの違い
表は共通点のないデータを並べて構成することも可能で、次のようなもの。
| 項目1 |
項目2 |
項目3 |
| 千代大海 |
10勝5敗 |
大関 |
| ドラえもん |
ネコ型ロボット |
四次元ポケット |
| レディガガ |
歌手 |
ファッション |
テーブルはある共通点を持ったレコードで構成され、次のようなもの。
| 社員ID |
社員名 |
年齢 |
| 000A |
加藤 |
40 |
| 000B |
藤本 |
32 |
| 001F |
三島 |
50 |
キーの種類
| キー名 |
説明 |
| 主キー |
主キーは、その値により必ず1行のレコードを
特定できるような列の組み合わせのこと。
(一意に識別できる) |
| 複合キー |
複数列を組み合わせて作る主キー |
| 候補キー |
主キーとして利用なキーが複数存在した場合の、
主キーの候補となるキー |
| スーパーキー |
主キーに、非キー列を付加した時のキーの組み合わせ |
| 外部キー |
2つのテーブル間の列同士で設定するもの。
外部キーは人間の親子関係のようなもので、
参照する側は参照元がないとデータを作れない
(親がいないと子は生まれない)。
テーブルに対して一種の『制約』を与え、
この制約を参照整合性制約という |
制約の種類
参照整合性制約の他に、テーブルの代表的な制約には次のものがある。
| 制約名 |
説明 |
| NOT NULL制約 |
NULLを禁止にする制約。各列ごとに設定できる。 |
| 一意制約 |
ある列の組について一位性を求める制約。
主キーと似ているが、主キーはテーブルに対して1個であるが、
一意制約は何個でも設定可能。 |
| CHECK制約 |
ある列の取りうる値の範囲を制限する。数値の範囲(20~65)や、
文字列のリスト('開発','人事','営業')みたいに指定できる。 |
正規化とは
概要
正規化とは、テーブルのレイアウトを正規形にするために行う論理設計の作業の一つ。正規形は、『データベースで保持するデータの冗長性を排除し、一貫性と効率性を保持するためのデータ形式』という意味。
正規化のポイント
正規化のポイントは3つ。
- 正規化とは更新時の不都合/不整合を排除するために行う
- 正規化は従属性を見抜くことで可能になる
- 正規形はいつでも非正規形に戻せる(正規化は無損失分解。可逆的な操作)
正規化のメリット、デメリット
| メリデメ |
内容 |
| メリット |
・データの冗長性が排除され、更新時の不整合を防止できる
・テーブルの持つ意味が明確になり、開発者が理解しやすい。 |
| デメリット |
・テーブル数が増え、SQL文の結合を多用するためパフォーマンスが悪化 |
どの程度すべきか
- 第3正規形までは原則必須
- 関連エンティティが存在する場合は、関連とエンティティが1対1に対応するようにする
正規形のレベル
正規形のレベルは全部で次の6種類あるが、一般的な業務の中で多く用いられるのは、第3までらしい。
- 第1正規形
- 第2正規形
- 第3正規形
- ボイスコット正規形
- 第4正規形
- 第5正規形
第1正規形の定義:スカラ値の原則
第一正規形の定義は、『1つのセルの中には1つの値しか含まない』というもの。
第一正規形の問題としては、テーブルの意味やレコードの単位をすぐに理解できないという点。データ上NULLとなってしまうものが主キーになるような場合、無理矢理にでも値を設定する必要が出てきて、後で参照するときに設定した意味を読み解く必要があるため。
また、そもそも『なぜ1つのセルに複数の値を設定してはだめ?』については、複数の値があると主キーが各列の値を一意に決定できなくなってしまうため。
第2正規形の定義:部分関数従属
主キーの一部の列に対して従属する列がある場合、この関係を部分従属と呼び、主キーを構成するすべての列に従属性がある場合を、完全関数従属と呼ぶ。
第2正規形とは、テーブル内で部分関数従属を解消し、完全関数従属のみのテーブルを作ることをいう。
従属というのは、会社コードが決まると会社名も定まるようなもので、その関係を{会社コード}->{会社名}と表現する。
イメージ的にはある関数fに会社コードを入力すると会社名が出力される(f(会社コード)=会社名)みたいな関係のことを言う。
よって、f(主キー)によってレコードが一意に定まる状態のことを言う。
第3正規形:推移的関数従属
{会社コード,社員ID}->{部署コード}->{部署名}のような2段階の関数従属があるようなものを推移的関数従属という。このような関係が成り立つ列がテーブル内にあると、『所属部員が現在たまたまいない部署』をデータベースに登録できなくなってしまう。
そこで、{会社コード,社員ID}->{部署コード}、{部署コード}->{部署名}のようにテーブルを分けてあげることで問題を解消する。
関数的なイメージは、g(f(会社コード,社員ID))=部署名となっている関数を、f(会社コード,社員ID)=部署コード、g(部署コード)=部署名の2つに分けてあげるような感じか🤔
ボイス-コッド正規形
第3正規形かつ『非キーから主キーへの関数従属をなくした状態』。ボイス-コッド正規形は非可逆分解になる可能性があるので注意する。
第4正規形
第4正規形では、独立な多値従属性が複数存在するテーブルを分割する。多値従属性とは、キーの値を1つ定めると複数の日キーの値が定まる状態のこと。
イメージ的には、1人の社員が複数のチームに所属し、複数製品を担当している関係を、{社員ID}-->{製品コード|チームコード}のように表す。このエンティティの関係をバラして、{社員ID}-->{製品コード}、{社員ID}-->{チームコード}のようなテーブルを分割してあげる。
第5正規形
第5正規形では、『関連がある場合は、それに対応する関連エンティティを作る』という作業を行う。
イメージとしては、{社員ID}-->{製品コード}、{社員ID}-->{チームコード}だけでは、チームが担当する製品がわからないので、{チームコード}-->{製品コード}という関連エンティティを追加してあげる。つまり事実として関連があるのであれば、それを関連エンティティとして追加する作業を行うということ。
参考