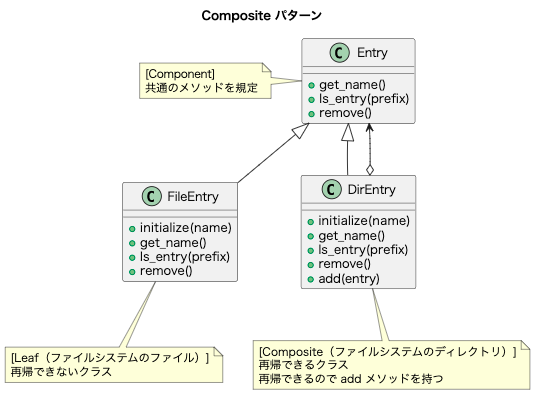
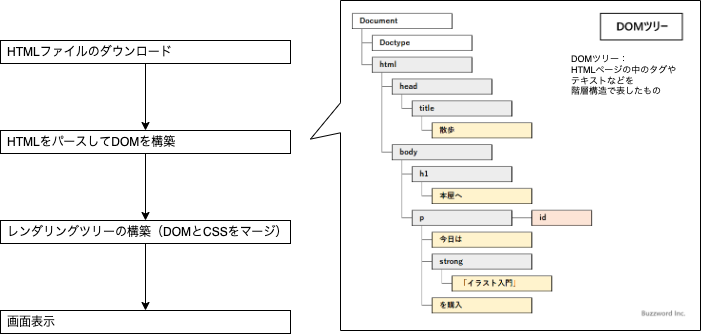
Webページが表示されるまでの流れ
Webページにアクセスすると、次のような手順でブラウザ上にWebページが表示される。
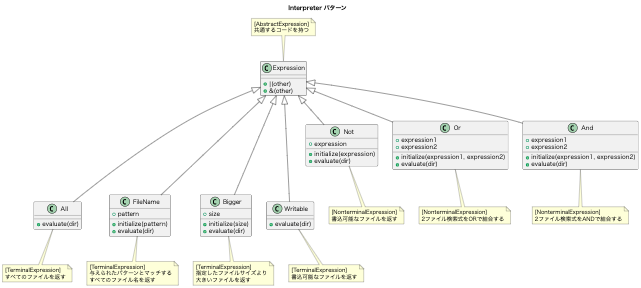
JavaScript では、DOMの各ノードに対して色々な操作を実行できる。
DOMの構築とは別に、スタイルシートデータからCSSOMが構築され、DOMとCSSSOMをマージして、レンダリングツリーが構築される。
一連の処理は、各ステップを順番に完了してから次のステップに進むのではなく、ある程度パースが完了したら、スタイルとマージして画面表示をしつつ、処理を継続するという流れになっている。
JavaScript がHTMLページの中に記述されている場合、パースを一旦停止して、<script> タグの中のコードを実行するため、<script> タグ以降の処理が遅くなる。
処理が遅くなる=画面表示が遅くなるに等しいため、ユーザ満足度が低くなるため望ましいものではない。
よって、<script> タグは HTML ページの最後(</body> の直前)に書くと良い。
ただ、全ての <script> タグをページの最後に書けばいいということでもない。画面表示前に処理したいことがあれば、<body> タグの最初や、<head>タグ内にコードを書く。
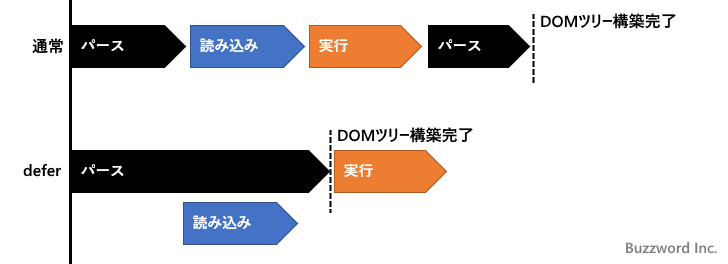
defer属性
defer 属性を使うと、<script> タグでのパース停止をしない。実行されるタイミングは DOM ツリーの構築完了後。
<script defer src="./jscode.js"></script>
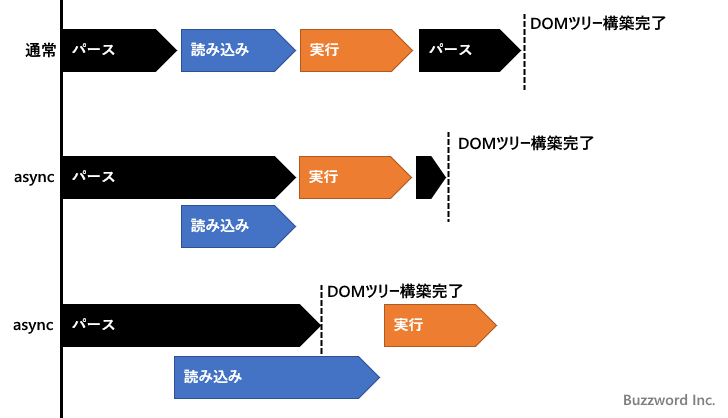
async属性
async 属性を使うと、<script> タグでのパース停止をしない。defer 属性との違いは、<sript> タグで読み込間れたコードは、DOMツリーの構築を待たず、読み込み完了後すぐに実行される点。
<script async src="./jscode.js"></script>
基本事項
プリミティブ型とオブジェクト型
JavaScriptのデータ型は、プリミティブ型とオブジェクト型の2種類。
- プリミティブ型
- 数値(整数および浮動小数点。64bit。データ型は
number) - 長数(数値型で扱えない大きな整数を扱う。データ型は
bigint) - 文字列(データ型は
string) - 論理値(データ型は
boolean) - undifined(値が代入されていないことを示す。データ型は
undefined) - null(値が代入されていないことを示す。明示的に代入することが可能。データ型は
object) - シンボル (ユニークな値を返す。データ型は
symbol)
- 数値(整数および浮動小数点。64bit。データ型は
- オブジェクト型
noscript要素
ブラウザで JavaScript が無効になっていると HTML ファイルの中に記述された JavaScript のコードは実行されない。その場合、利用者は何も表示されないため、状況がわからない。
そこで、 JavaScript が無効になっている時にだけ別のコンテンツを表示する機能がある。それが noscript 要素。
下記はJavaScript 無効にした時のWebページ。JavaScript が無効なので、何も表示されない。
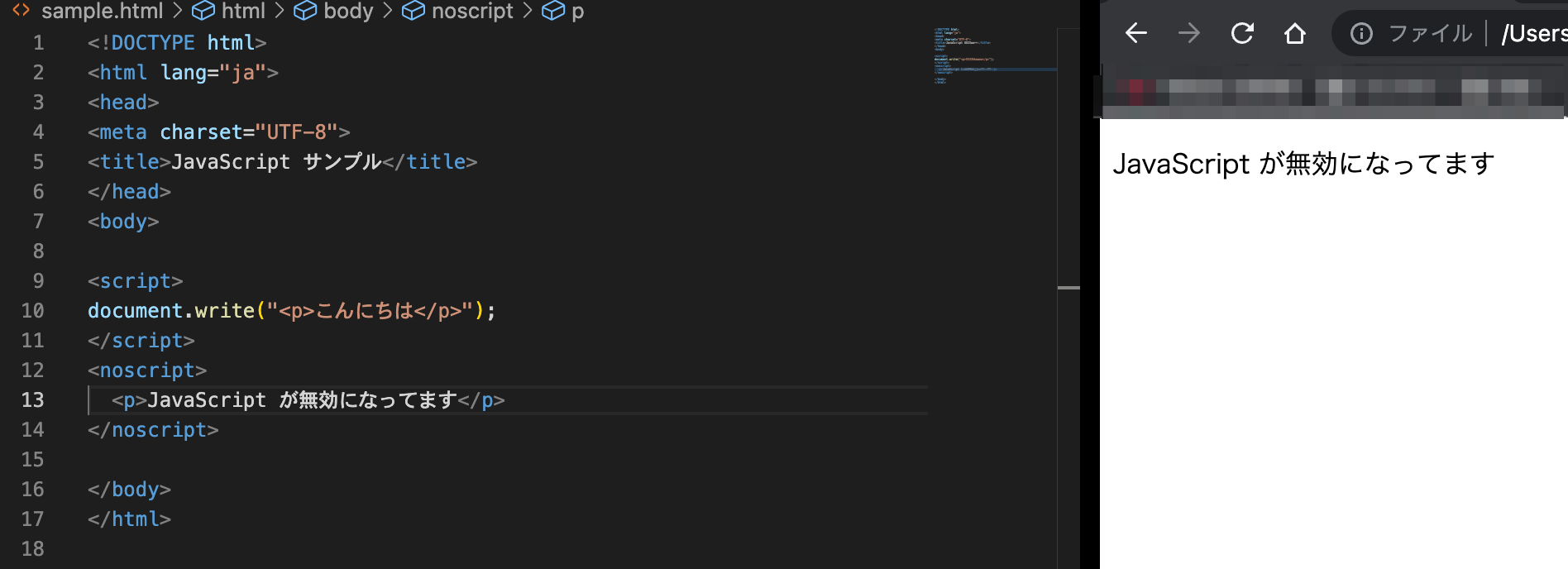
次に、noscript 要素を使ってみると、次のようにメッセージが表示される。
strictモード(非推奨コードの制限)
JavaScript では、文法的にエラーではないが、推奨でないコード記述が可能。例えば、次のようなもの。
// 未宣言の変数に代入
let myage;
myoge = 20;
// 引数名の重複
function test(a, a, b){
console.log('a = ' + a);
console.log('b = ' + b);
}
test(1, 2, 3);
// >> a = 2
// >> b = 3
上記のような非推奨のコード記述をエラーとするために、strict モードがある。使う時には次のようにする。
// プログラム全体に適用するときは、プログラムの先頭に書く
'use strict';
・・・
// 特定の関数にのみ適用するときは、関数の先頭に書く
function myFunc(){
'use strict';
・・・
}
falseとみなされる値
次の論理値は全て false とみなされる。
false, 0, -0, 0n, ""(空文字), null, undifined, NaN
そして、上記以外のものは、全て true とみなされる。
長数の書き方
長数は数値リテラルで表すことができる最大数値 253-1を超えるような数値を演算したい時に使う整数。超数を使う時には、下記のようにnをつける。
let num = 854n;
使える算術演算子は、+, -, *, /, %, ** で長数同士に対して利用できる。そのほか、ビット演算やシフト演算、等価演算など、数値リテラルと大体同じ操作ができる。
文字列
テンプレートリテラル
文字を入力するときは、シングルクォート、ダブルクォート、バッククォートが使える。シングルクォートとダブルクォートの違いはない。
バッククォートで括った文字列をテンプレートリテラルといい、テンプレートリテラルでは文字列中の改行をそのまま扱えたり、式を埋め込んで使うことができる。
// 文字列の改行をそのまま扱える
let msg = `こんにちは。
今日は天気がとてもいいですね。`;
console.log(msg);
// => こんにちは。
// => 今日は天気がとてもいいですね。
// 式を埋め込む
let name = 'オレンジ';
let cost = 100;
let msg = `今日の${name}の値段は${Math.trunc(cost*1.1)}円です。`;
console.log(msg);
// => 今日のオレンジの値段は110円です。
文字列操作でできること
String オブジェクトでは、色々な文字列操作ができる。
文字列を分割する
js 文字列.split([区切り文字[, 最大分割回数]])文字列を置換する
js 文字列.replace(置換する文字列, 新しい文字列)複数の文字列を結合する
js 文字列.concat(文字列[, 文字列, ...])文字列を繰り返す
js 文字列.repeat(回数)開始位置と終了位置を指定して部分文字列を取得する
js // 開始インデックスから終了インデックスまでを切り取る 文字列.slice(開始インデックス[, 終了インデックス]) 文字列.substring(開始インデックス[, 終了インデックス])違いは、次の2つ。
- インデックスに負の値を指定した時、
sliceが最後尾からの順番に対して、substringでは0を指定したものとみなす - 終了インデックスが開始インデックスよりも小さい場合、
sliceは空文字、substringはインデクスを入れ替えて表示する
- インデックスに負の値を指定した時、
開始位置と文字数を指定して部分文字列を取得する
js 文字列.substr(開始インデックス[, 文字数])指定位置の文字を取得する
js 文字列.charAt(インデックス)大文字を小文字にする
js 文字列.toLowerCase()小文字を大文字にする
js 文字列.toUpperCase(指定文字を検索し、見つかる場合は最初の位置を返す
```js // 文字列を先頭から検索 文字列.indexOf(検索文字列 [, 開始インデックス])
// 文字列の最後から検索 文字列.lastIndexOf(検索文字列 [, 開始インデックス]) ```
指定文字列が含まれているかを判定する
js 文字列.includes(検索文字列 [, 開始インデックス])文字列の先頭、末尾が指定文字列かを判定する
```js // 文字列の先頭を調べる 文字列.startsWith(検索文字列 [, 開始位置])
// 文字列の末尾を調べる 文字列.endsWith(検索文字列 [, 開始位置]) ```
文字列の先頭または末尾から空白、タブ、改行を取り除く
```js // 文字列の先頭と末尾から空白、タブ、改行除去 文字列.trim()
// 文字列の先頭から空白、タブ、改行除去 文字列.trimStart()
// 文字列の末尾から空白、タブ、改行除去 文字列.trimEnd() ```
文字列が指定長になるように先頭または末尾に文字を追加
```js // 先頭に文字列を追加して指定長にする 文字列.padStart(文字列の長さ [, 埋め込む文字列])
// 末尾に文字列を追加して指定長にする 文字列.padEnd(文字列の長さ [, 埋め込む文字列]) ```
変数宣言の種類
変数宣言の種類は、let, var, const がある。性質は次のもの。
let基本的には、これを用いれば良い。
letを用いる場合は、再宣言が禁止されている。js let num = 9; num = 10; // 再代入は可能 let num; // 再宣言は不可 //=> VM18:3 Uncaught SyntaxError: Identifier 'num' has already been declaredまた、スコープについてはブロックとなっている。
js function test(num){ if (num >= 20){ let msg = '成人です'; }else{ let msg = '未成年です'; } console.log(msg); // ifブロック外で参照不可 } test(10); //=> VM293:7 Uncaught ReferenceError: msg is not defined //=> at test (<anonymous>:7:17) //=> at <anonymous>:9:3const
constは変数の宣言時に必ず初期値を設定する必要があり、再宣言、再代入ともに不可。```js const num = 9; num = 10; // 再代入不可 //=> VM189:3 Uncaught SyntaxError: Identifier 'num' has already been declared
const num; const num; // 再宣言不可 //=> VM261:1 Uncaught SyntaxError: Missing initializer in const declaration ```
var
特徴的な振る舞いをする。
letが使えるならわざわざ使う必要ない印象。再宣言、再代入ともに可能。js var num = 9; var num = 10; // 再宣言可能 num; //=> 10 num = 8; // 再代入可能 num; //=> 8スコープは、関数スコープとなっている。
js function test(num){ if (num >= 20){ var msg = '成人です'; }else{ var msg = '未成年です'; } console.log(msg); // ifブロック外でも参照可 } test(10); //=> 未成年です
繰り返し処理
複数の変数を変化させる
C++ で『できたらいいな〜』とたまに思うことがあった複数の初期化式を JavaScript では扱える。
for (let i = 0, j = 3; i < 3; i++, j--)
{
console.log(i + "," + j );
}
//=> 0,3
//=> 1,2
//=> 2,1
素晴らしい😄
プロパティ名を取得
// jsの場合
// sample1
const fruit = {orange:170, apple:90, lemon:110};
for (let i in fruit){
console.log(i + ', ' + fruit[i]);
}
// sample2
const fruit = ['orange', 'apple', 'lemon'];
for (let i in fruit){
console.log(fruit[i]);
}
上のコードをC++で書いてみると下記のような感じになる。
// c++の場合 // sample1 unordered_map<std::string, int> fruits{ {"orange", 170}, {"apple", 90}, {"lemmon", 110}, }; for (auto& fruit : fruits) { std::cout << fruit.first << ", " << fruit.second << std::endl; } // sample2 std::string fruits2[3] = {"orange", "apple", "lemon"}; for (auto& fruit : fruits2) { std::cout << fruit << std::endl; }
配列
length プロパティで要素数を操作
『変わってるな🧐』と思ったのは、length プロパティで要素数を操作できる点。
let data = [10, 42, 52, 28, 26]; console.log(data); //=> [10, 42, 52, 28, 26] data.length = 2; // 要素を2つにする console.log(data); //=> (2) [10, 42]
指定位置の要素を置き換える
便利だなと思ったのは、splice メソッドでこいつは指定位置から指定要素数分、要素を置き換える。フォーマットは次のようになっている。
配列名.splice(開始インデックス, 削除する要素数, 追加要素1, 追加要素2, ...)
例えば次のような感じで配列を操作できる。
let alpha = ['A', 'B', 'C', 'D', 'E']; alpha.splice(1, 2, 'X', 'Y', 'Z'); console.log(alpha); //=> ["A", "X", "Y", "Z", "D", "E"] alpha.splice(1, 2); console.log(alpha); //=> ["A", "Z", "D", "E"] alpha.splice(2, 0, 'a', 'b'); console.log(alpha); //=> ["A", "Z", "a", "b", "D", "E"]
forEach と for , for...ob の違い
Array オブジェクトには繰り返し処理用に forEach メソッドがある。要素を取り出して、コールバック関数に渡して処理ができる。
fruit.forEach(function(element, index, array){
console.log('Index:' + index);
console.log('Element:' + element);
console.log('Array:' + array);
});
//=> Index:0
//=> Element:Apple
//=> Array:Apple,Melon,Orange
//=> Index:1
//=> Element:Melon
//=> Array:Apple,Melon,Orange
//=> Index:2
//=> Element:Orange
//=> Array:Apple,Melon,Orange
for 文、 for...ob でも同じことができるが、違いとして forEach では存在しない要素に対して処理を行わない。
let alpha = ['A', 'B', , , 'C'];
alpha.forEach(function(element){
console.log(element);
});
//=> A
//=> B
//=> C
for (let i = 0 ; i < alpha.length ; i++){
console.log(alpha[i]);
}
//=> A
//=> B
//=> undefined
//=> undefined
//=> C
for (let element of alpha){
console.log(element);
}
//=> A
//=> B
//=> undefined
//=> undefined
//=> C
二次元要素のconcatでの複製に注意
concat で一次元要素の配列の複製はクローンで、多次元要素を持つ配列の複製を行う時には参照になることに注意。
一次元配列の場合
```js let fruit = ['Apple', 'Melon', 'Orange']; let copyFruit = fruit.concat();
copyFruit[1] = 'Grapes'; console.log(copyFruit); //=> ["Apple", "Grapes", "Orange"]
console.log(fruit); //=> ["Apple", "Melon", "Orange"] // オリジナルは変わらない ```
多次元配列の場合
```js let result = [[78, 92], [68,76]]; let copyResult = result.concat();
copyResult[0][1] = 84; console.log(copyResult[0]); //=> [78, 84]
console.log(result[0]); //=> [78, 84] // 参照なのでオリジナルも変わる ```
配列要素の検索
配列では要素を検索するメソッドが用意されている。
| メソッド名 | 概要 | 戻り値 |
|---|---|---|
findIndex |
条件に最初に一致するインデックスを取得 | インデックス |
find |
条件に最初に一致する値を取得する | 値 |
some |
配列内に条件に一致する要素があるかを判定 | 真偽値 |
every |
配列の全要素が条件に一致するかを判定 | 真偽値 |
条件式は次のようにコールバック関数として書く。
let result = [75, 68, 92, 84, 90];
// findIndexメソッド
let target = result.findIndex(function(element){
return element > 85;
});
console.log(target);
//=> 2
// findメソッド
let target = result.find(function(element){
return element > 85;
});
console.log(target);
//=> 92
// someメソッド
let target = result.some(function(element){
return element > 85;
});
console.log(target);
//=> true
// everyメソッド
let target = result.every(function(element){
return element > 85;
});
console.log(target);
//=> false
要素の並び替え
配列の並び替えには2つのメソッドがある。両メソッドは、並び替えの結果を新しい配列として返すのではなく、自身を直接更新するので注意が必要。
| メソッド名 | 概要 |
|---|---|
reverse |
要素を逆順にする |
sort |
コールバック関数がなければ要素を文字列変換し並び替える。ある場合、コールバック関数の戻り値により並び替えを変える。 ・戻り値が負:1つ目の要素を2つ目よりも小さいインデックス ・戻り値が0:何もしない ・戻り値が正:2つ目の要素を1つ目よりも小さいインデックス |
簡単に処理のまとめるとした図のような感じになる。
let number = ['100', '20', '3'];
number.reverse();
console.log(number);
//=> ["3", "20", "100"]
number.sort();
console.log(number);
//=> ["100", "20", "3"]
number.sort(function(first, second){
return first - second;
});
console.log(number);
//=> ["3", "20", "100"]
要素の抽出
上記で示した検索の他に、条件を満たす要素を抽出し、新しい配列を生成することも可能。その場合、filter メソッドを用いる。
filter メソッドでは、コールバック関数の戻り値が true となるものを新しく配列に追加する。
let result = [48, 75, 92, 61, 54, 83, 76];
let filterResult = result.filter(function(element){
return element > 70;
});
console.log(result);
//=> [48, 75, 92, 61, 54, 83, 76]
console.log(filterResult);
//=> [75, 92, 83, 76]
要素の総和を計算する
Array オブジェクトの reduce メソッドを用いると、配列内の要素の値の総和を計算できる。reduce メソッドには、コールバック計算結果を保管できる変数を持っている点がポイント。
reduce メソッドの第二引数で保管値の初期値を設定できる。設定しない場合は、最初の要素が設定されるが、下記のような場合にうまくいかなくなるので、基本的に初期値を設定しておくと良さそう。
let user = [
{ name:'Yamada', result:75 },
{ name:'Suzuki', result:91 },
{ name:'Kudou', result:80 }
];
let total = user.reduce(function(sum, element){
return sum + element.result;
}, 0); // sum が0で初期化
console.log(total);
//=> 246
reduceなのに総和??
『reduce(減らす)なのに、総和なんかい🤯』となんでこの名前なのかが気になってしまい、少し調査。
Array.prototype.reduce() - JavaScript | MDN によると、reduce メソッドではコールバックを呼び出す際に、直前の要素の計算結果を引き継げる仕組みを持っており、引き継いだ結果を『まとめた』結果を返す。
英単語の『reduce』には『減らす』の他に、『まとめる』や『変える』という意味もあり、後者の意味で用いられているようでした。中学英語レベルの自分としては、『減らす』にどうしても意味が引っ張られてしまいます😅
よって、reduce メソッドで総和も計算できるし、例えば上記リンクでは、2次元配列を1次元配列にするといった処理も紹介されていました。すっきりした😏
配列の分割代入
配列の要素を複数の変数にまとめて代入できる。
// 分割代入しない場合 let personal = ['Yamada', 10, 'Tokyo']; let name = personal[0]; let old = personal[1]; let address = personal[2]; // 分割代入する場合 let personal = ['Yamada', 10, 'Tokyo']; let [name, old, address] = personal;
関数
関数化しておくことで、再利用をすることができコードのDRY化につながる。
関数の種類
function キーワードを用いる
// テンプレート
function 関数名(引数1, 引数2, ...){
実行される処理1;
実行される処理2;
...
return 戻り値;
}
// サンプル
function dispTotal(x, y){
let sum = x + y;
return sum;
}
let result = dispTotal(3, 4);
console.log(result);
//=> 7
Function コンストラクタを用いる
他の方法との違いもないため、そんな利用することはないらしい。
// テンプレート
let 変数名 = new Function('引数1', '引数2', ..., '実行する処理1';`実行する処理2`);
//サンプル
let dispTotal = new Function('x', 'y', 'let sum = x + y;return sum');
let result = dispTotal(3, 4);
console.log(result);
//=> 7
関数リテラルを用いる
関数リテラルで定義された関数は、変数代入や関数呼び出し時に引数として指定することができる。
// テンプレート
let 変数名 = function(引数1, 引数2, ...){
実行される処理1;
実行される処理2;
...
return 戻り値;
};
// サンプル
let dispTotal = function(x, y){
let sum = x + y;
return sum;
};
let result = dispTotal(3, 4);
console.log(result);
//=> 7
関数リテラルでは名前をつける必要がなく、無名関数として利用することもできる。無名関数は、一度きりの使い捨て関数みたいなもので、他から呼び出すことのできない関数になっている。イベント処理やコールバック関数としての用途がある。
function dispNum(x, y, func){ // 第3引数が無名関数
console.log(func(x, y));
}
dispNum(10, 8, function(x, y){ // 呼び出し側で第3引数に無名関数を渡している
return (x + y) / 2;
});
>> 9
アロー関数式を用いる
アロー関数式では、関数定義を省略して記述することができる。
// テンプレート
let 変数名 = (引数1, 引数2, ...) => {
実行される処理;
...
return 戻り値;
};
// サンプル
let dispTotal = (x, y) => {
return x + y;
};
let result = dispTotal(3, 4);
console.log(result);
//=> 7
// サンプル(省略形)
let dispTotal = (x, y) => x + y;
let result = dispTotal(3, 4);
console.log(result);
//=> 7
可変長引数
呼び出し側から渡されてきた要素全てを配列として格納する仮引数のことを可変長引数(Rest Paramter)と呼ぶ。
function calcSum(...num){
return num.reduce((sum, element) => sum + element, 0);
}
calcSum(1, 2, 3);
//=> 6
calcSum(1, 2, 3, 4, 5);
//=> 15
通常の引数と合わせて使用することもできる。その場合、可変長引数は最後に記述する。
function 関数名(引数1, 引数2, ...引数3){
...
}
HTML内での関数記述位置
大雑把には、呼び出し側よりも前に関数が定義されていれば、呼び出し時にエラーとなることはないと覚えておけば良さそう。
関数の中に関数を定義
JavaScript では関数の中に関数を定義することができる。関数内で定義された関数のスコープは、関数内スコープなので関数外から呼び出すことはできない。
function dispHello(){
console.log('Hello');
function dispBye(message){
console.log(message);
}
dispBye('関数内スコープ');
}
dispHello();
//=> Hello
//=> 関数内スコープ
dispBye('関数外スコープ');
//=> Uncaught ReferenceError: dispBye is not defined
関数とオブジェクトの関係
JavaScript では関数もオブジェクトの一つで、関数を定義すると、関数名の変数に関数オブジェクトが代入される。
function calcTotal(x, y){
return x + y;
}
console.log(calcTotal);
//=> calcTotal(x, y){
//=> return x + y;
//=> }
関数を変数に代入したり、他の関数の引数に使うときには、関数リテラルを使う方法が用いられる。
let calcTotal = function(x, y){
console.log(x + y);
}
let calcAbs = function(x, y){
console.log(Math.abs(x - y));
}
function echo(value1, value2, func){
func(value1, value2);
}
echo(1, 2, calcTotal);
//=> 3
echo(3, 4, calcAbs);
//=> 1
例外処理
例外の種類
例外のエラー種類は8種類のグローバルオブジェクトで定義されている。
| 例外名 | 概要 |
|---|---|
Error |
一般的なエラー |
EvalError |
eval関数に関するエラー |
InternalError |
JavaScriptの内部エラー |
RangeError |
数値が有効範囲を超えた場合のエラー |
ReferenceError |
不正な参照を行った場合のエラー |
SyntaxError |
JavaScriptの構文エラー |
TypeError |
変数や引数の型が適切ではない場合のエラー |
URIError |
encodeURIまたはdecodeURIに関するエラー |
上記のオブジェクトを使うことで、各例外発生時の振る舞いを変えることができる。
function returnFixed(num, digits){
try{
console.log(num.toFixed(digits));
} catch(e) {
if (e instanceof RangeError){
console.log('RangeError');
} else if (e instanceof TypeError){
console.log('TypeError');
} else {
console.log(e);
}
}
}
returnFixed(3.87654, 3);
//=> 3.877
returnFixed(3.87654, 1000);
//=> RangeError
returnFixed('3.87654', 1000);
//=> TypeError
例外の有無によらず処理をさせる
JavaScript には try...catch...finally 文がある。try ブロックではブロック内処理の例外を捕捉し、catch ブロックでは例外捕捉時の処理を行い、 finally では例外の有無によらず文の最後に処理を実行する。
// format
try{
例外が発生する可能性がある文を記述
・・・
} catch(e) {
例外をキャッチしたときに実行される処理
・・・
} finally {
最後に実行される処理
・・・
}
// sample
function sum(a, b){
try{
console.log(a + b);
} catch(e) {
console.error(e);
} finally {
console.log('Finally!');
}
}
sum(10, 8);
//=> 18
//=> Fnally!
sum(10, 8n);
//=> Fnally!
コールバック関数内の例外はキャッチできない
コールバック関数が実行されるのは、try の外であるため例外をキャッチできないという話。
// コールバック関数じゃない場合はキャッチできる
console.log('start');
//=> start
try{
10 + 8n;
} catch(e) {
console.log(e);
//=> Cannot mix BigInt and other types, use explicit conversions
}
console.log('end');
//=> end
// コールバック関数の場合はキャッチできない
console.log('start');
//=> start
try{
setTimeout(function sum(a, b){
console.log(a + b);
},2000, 10, 8n);
} catch(e) {
console.log(e);
}
console.log('end');
//=> end
正規表現
JavaScript での正規表現の定義方法
-
```js // format /パターン/ /パターン/フラグ
// sample let regexp1 = /[a-zA-Z]{4}/; console.log(regexp1.test("1AbCd2")); //=> true
let regexp2 = /apple/; console.log(regexp2.test("1Apple2")); //=> false regexp2 = /apple/i; console.log(regexp2.test("1Apple2")); //=> true ```
-
```js // format new RegExp(パターン[, フラグ])
// sample let regexp1 = new RegExp('[a-zA-Z]{4}'); console.log(regexp1.test("1AbCd2")); //=> true let regexp2 = new RegExp('apple', 'i'); console.log(regexp2.test("1Apple2")); //=> true ```
JavaScript の正規表現で利用できるフラグ
JavaScript では6種類のフラグが用意されている。
| フラグ | フラグ名 | 説明 |
|---|---|---|
g |
Global | フラグなしだと最初にマッチした文字列のみで、フラグありだと検索文字列全体にする |
i |
IgnoreCase | 大文字小文字区別なし |
m |
Multiline | フラグなしだとメタ文字 ^, $ のマッチは文字列の先頭と末尾のみで、フラグありだと行頭と行末も含める |
s |
DotAll | フラグなしだと任意の一文字の . は改行を含めない、フラグありだと含める |
u |
Unicode | フラグなしだとUnicode形式で指定しない、フラグありだと指定する |
y |
Sticky | フラグなしだと検索対象は全体で、フラグありだと指定した開始位置からのみマッチするかを判定 |
正規表現の使い方
| フォーマット | 説明 |
|---|---|
正規表現オブジェクト.test(文字列) |
対象となる文字列が正規表現とマッチするかのブール値を返す |
正規表現オブジェクト.exec(文字列) |
マッチした文字列を取得する |
文字列.search(正規表現オブジェクト) |
マッチした最初の文字列の先頭文字のインデックスを返す。マッチしない場合は-1を返す |
文字列.match(正規表現オブジェクト) |
文字列の正規表現とマッチする部分文字列を取得する。マッチしなかった場合は null になるので要素取得時には例外処理などを入れる必要がある。 |
文字列.split([正規表現[, 最大分割回数]]) |
対象文字列を、正規表現オブジェクトで分割し、それぞれを要素とした配列を返す |
文字列.replace(正規表現, 新しい文字列) |
対象文字列を、正規表現オブジェクトにマッチする部分を置換する |
Mathオブジェクト
小数点以下の加工
Math オブジェクトには小数点以下を加工する静的メソッドが用意されている。
| メソッド名 | 概要 |
|---|---|
Math.round |
四捨五入 |
Math.ceil |
切り上げ |
Math.floor |
切り下げ |
Math.trunc |
切り捨て |
floor と trunc の違いが分かりにくいが、floor は文字通り切り下げる。
// 正の場合 const a = 2.82; console.log(Math.floor(a)); //=> 2 console.log(Math.trunc(a)); //=> 2 // 負の場合 const b = -2.82; console.log(Math.floor(b)); //=> -3 console.log(Math.trunc(b)); //=> -2
コンソール出力
コンソール出力の違い
コンソール出力メソッドには、以下4種類がある。
| メソッド名 | コンソール出力 |
|---|---|
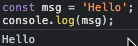
console.log |
 |
console.info |
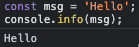 ※Google Chrome だと log と違いなしだが、Fire Fox だと 『i』 アイコンがつく |
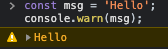
console.warn |
 |
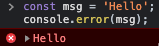
console.error |
 |
上記のようにコンソール出力のレベルを変えることで、開発者ツールのコンソール上でフィルタ機能を活用しやすくなる(エラーだけ表示等)。
コンソール上でオブジェクトを展開
コンソール出力するメソッドにオブジェクトを渡すと、コンソール上で展開することが可能。デバッグの時などに重宝しそう。
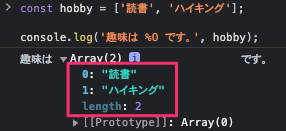
呼び出された経路の表示
console.trace メソッドでは、console.traceメソッドが呼び出された経路をコンソール出力することができる。
function funcA(){
console.trace();
}
function funcB(){
funcA();
}
funcA();
//=> console.trace
//=> funcA
//=> (anonymous)
funcB();
//=> console.trace
//=> funcA
//=> funcB
//=> (anonymous)
Ajax
Ajaxとは
Ajax は Asynchronous JavaScript + XML の略で、Webサーバとブラウザ間を非同期通信する方法のこと。
Ajax を利用することでページの切り替えなしで表示内容を更新できるようになる。例えば、クライアントから一部の情報をリクエストして、サーバからの応答が返ってきたら、その情報を反映する。
上記の『一部の情報』という点がポイントのようで、ブラウザ上の全ての情報を更新するのではなく、部分的なリクエストにすることで、更新がない部分は残したままブラウザ画面を更新できるらしい。
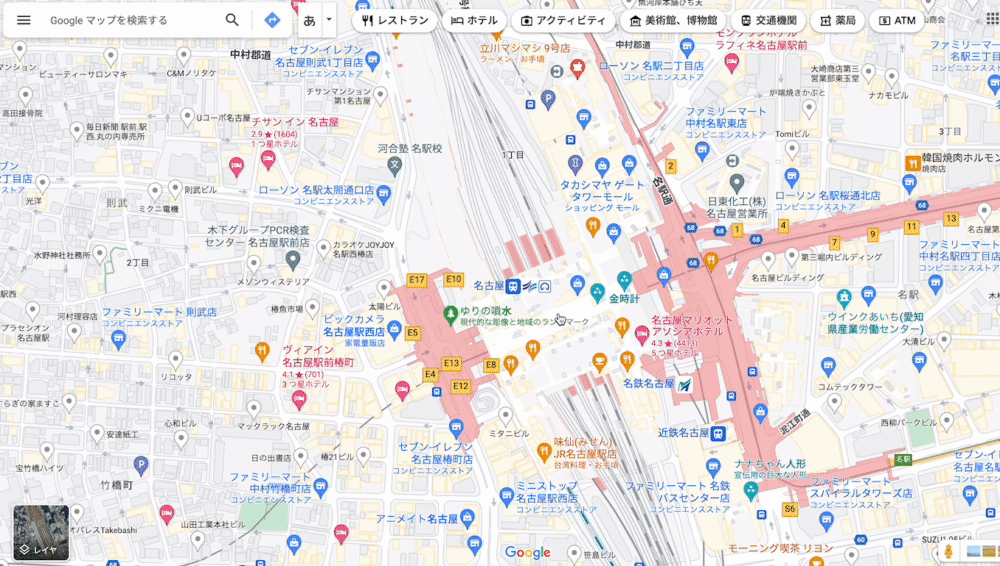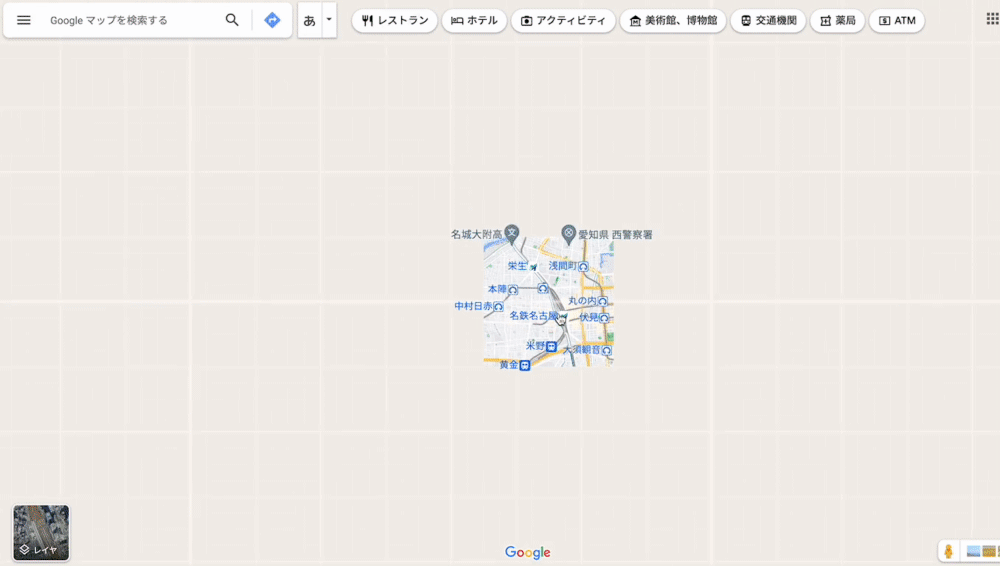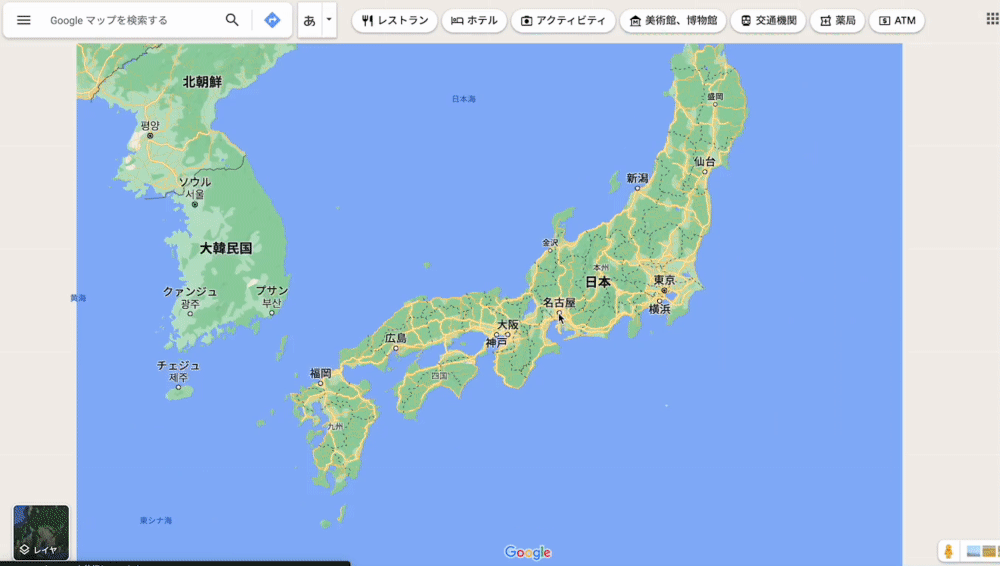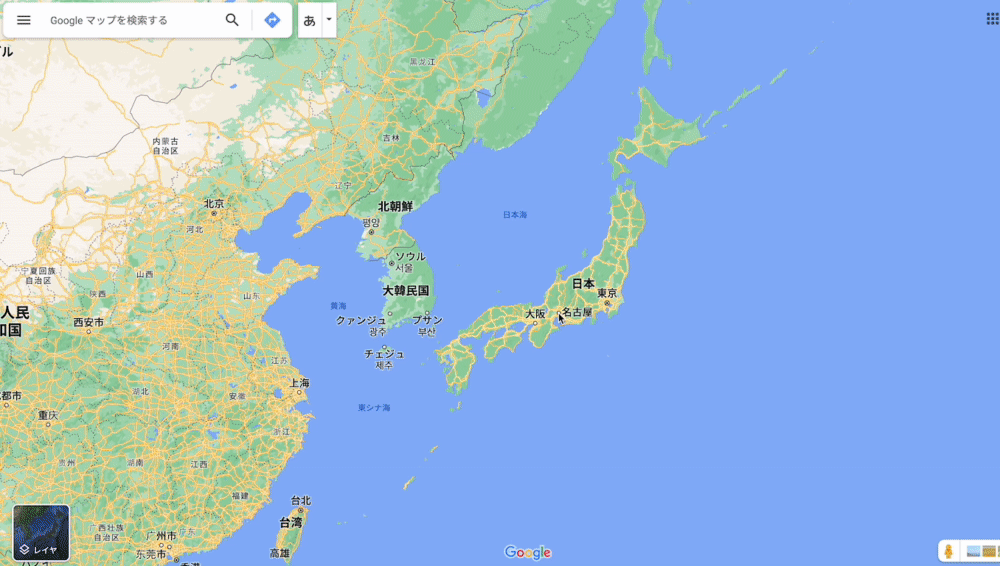
例えば、Google マップの縮小時に広域エリアが表示されてなくても、すぐに表示されるようになるのは裏で Ajax が動いているかららしい。
Ajax を支える XMLHttpRequest オブジェクト
上記のような非同期通信のために使用するのが、 HMLHttpRequest オブジェクト。このオブジェクトがサーバと通信を行い、リクエストに対するデータ受信が完了したらコールバック関数にて受信データを処理する。
大雑把には、次のような流れで Ajax 通信が行われる。
XMLHttpRequestオブジェクト生成XMLHttpRequest.openによる通信方法の設定XMLHttpRequest.sendでリクエストをサーバーへ送信
非同期通信では、サーバからのレスポンスの受信完了時にコールバックを呼び出すので、それを検知するために、HMLHttpRequest オブジェクトには状態を表すプロパティがある。
| 値 | 説明 |
|---|---|
| 0 | 未初期化(openが未実施) |
| 1 | ロード中(open設定済み、send未実施) |
| 2 | ロード済(send済、レスポンス待ち) |
| 3 | 受信中 |
| 4 | 完了 |
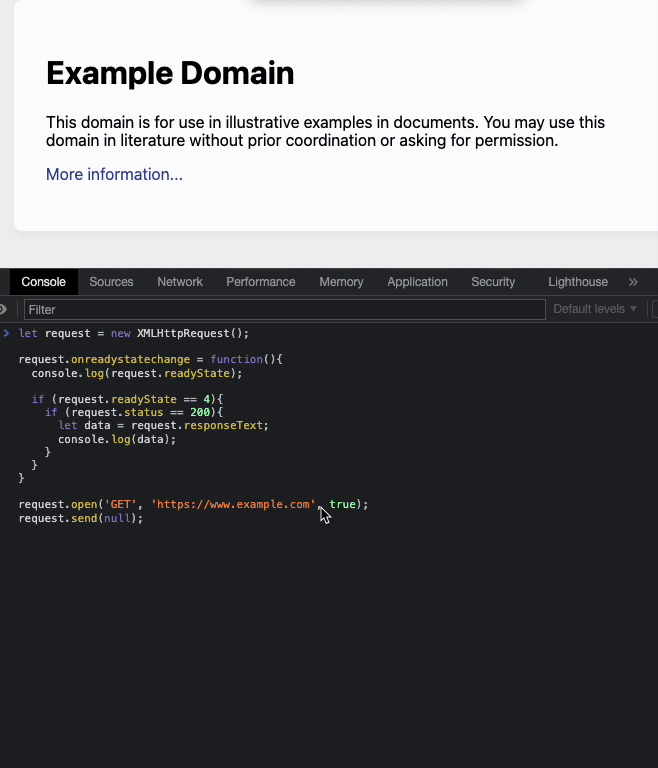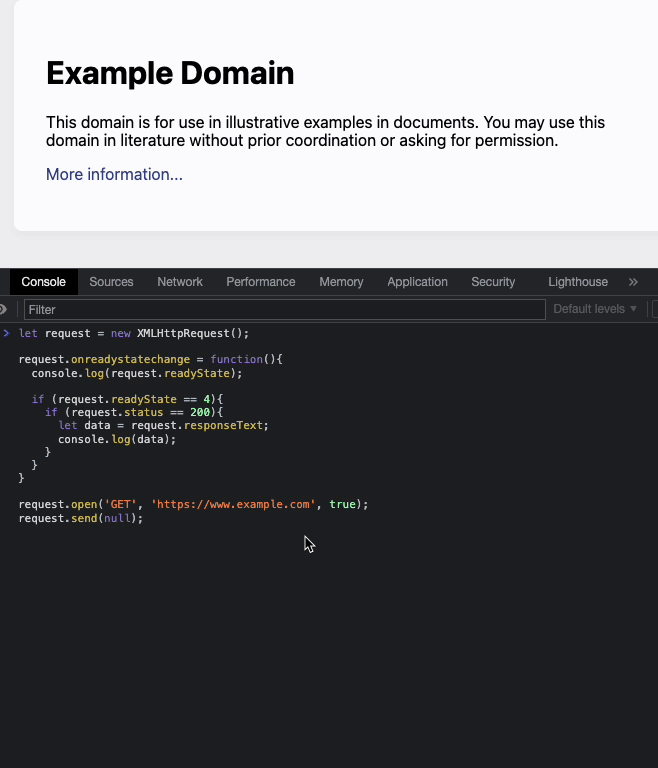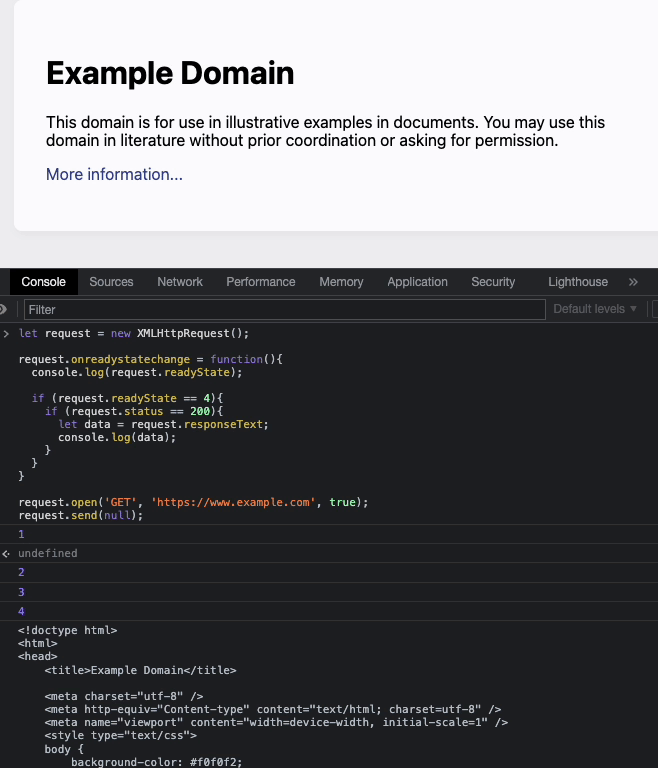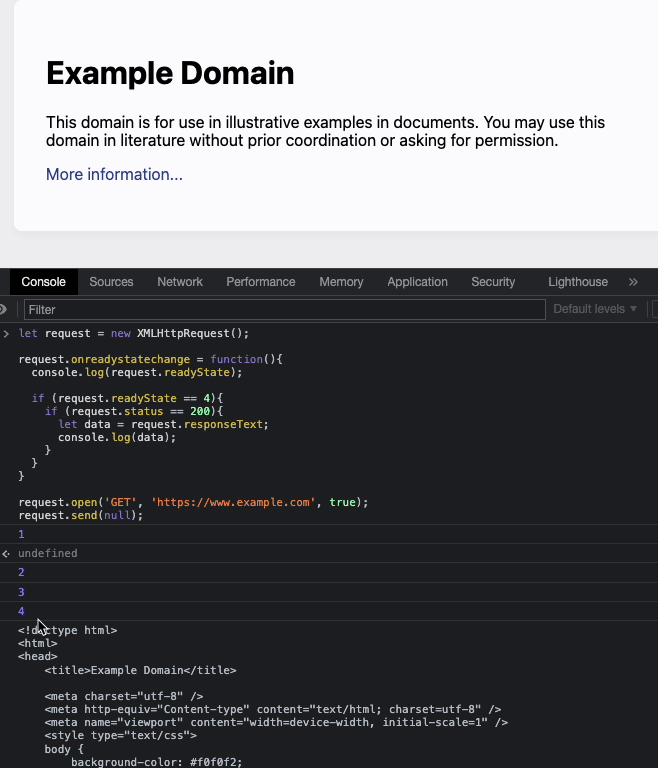
上記の状態をチェックすることで、処理を切り替え非同期処理を実現する。簡単に流れを確認してみるために、次のようなコードを用意。
let request = new XMLHttpRequest();
request.onreadystatechange = function(){
console.log(request.readyState);
if (request.readyState == 4){
if (request.status == 200){
let data = request.responseText;
console.log(data);
}
}
}
request.open('GET', 'https://www.example.com', true);
request.send(null);
https://www.example.com を開き、デベロッパーツールのコンソールに上記コードを貼り付けて実行すると、状態が切り替わっていくことが確認できた。