読みやすいコードを書くコツ
リーダブルコードを読んだので、大事だなと思ったことをまとめる。
第一部:表面上の改善
第二章:名前に情報を詰め込む
ここでのポイントは、名前は短いコメントであると考えること。いい名前をつければ、それだけ多くの情報を伝えることができるようになるため。じゃあ、どんな名前がいい名前なの?🧐ってことだけど、本では下記のテーマとポイントが紹介されていた。
| テーマ | ポイント |
|---|---|
| 明確な単語を選ぶ | 気取った言い回しよりも明確で正確な名前にする。類語辞典などでより明確なものを選んであげるのが有効 |
| 汎用的な名前を避ける (または使う状況を選ぶ) |
変数の値を表すような名前にする。tmpのような名前は、情報の一時保管として使用するような時に使う。 |
| 抽象的な名前よりも具体的な名前を使う | メソッドの動作をそのまま表すような名前にする |
| 接尾辞や接頭辞を使って情報を追加 | N進数や単位、危険や注意を喚起する情報を追加する |
| 名前の長さを決める | スコープが小さければ(スコープが数行の変数)短い名前でもよい。名前の省略形を使う場合は、一般的に使用されるものを使用する(stringをstr、documentをdocみたいな感じ)。無くても意味が変わらないならその単語を削除する |
| 名前のフォーマットで情報を伝える | クラス名をキャメルケース、変数名をスネークケースというように、名前のフォーマットを見るだけで情報が伝わるようにする。 |
第三章 誤解されない名前
ここでのポイントは、名前が他の意味と誤解されないかどうかを自問自答するという点。書いたコードが、意図通り正しく理解できるような名前となっているかを意識することが大事。どんなことに気をつけるかは、下記が紹介されていた。
| 使用する場面 | 説明 |
|---|---|
| 上下の限界値を決める | max_やmin_を接頭辞にする。 |
| 包含的範囲(最終要素も含める) | firstやlastを使用する |
| 包含/排他的範囲(最終要素を含めない) | beginとendを使用する |
| ブール値を扱う | isやhasを使う |
上記以外にも、『肯定形で単語を利用する』、『単語に対するユーザの期待に沿うような名前付け(get()やsize()のようなものは軽量なメソッドであるということが一般的に浸透している)を意識する』なども重要とのことだった。
第四章 美しさ
ここでのポイントは、見た目が美しいコードの方が使いやすいという点。さっと流し読みができるのが、誰にとっても使いやすいコードと言える。コードを読みやすくするためには、3つの原則が大事とのこと。
- 読み手が慣れているパターンと一貫性のあるレイアウトを使う
- 似ているコードは似ているように見せる
- 関連するコードはまとめてブロックする
上記の原則を基に、具体的に気をつけることは下記が紹介されていた。
| 要点 | 説明 |
|---|---|
| 一貫性のある簡潔な改行位置 | 複数のコードブロックで同じようなことをしていたら、改行位置を揃えて、シルエットも同じようにする |
| メソッドを使った整列 | 複数のコードブロックで同じようなことをしていたら、ヘルパーメソッドを用いてテストケースの大切な部分が見えやすくできないかを考え、シルエットも同じようにする |
| 縦の線をまっすぐにする | 空白などを用いて列を整列させ、概要を把握しやすくする |
| 一貫性と意味のある並び | 重要度順、アルファベット順、入力フォームと同じ順など、意味なる並びがあればそれに従わせる。また、ある場所でA・B・Cと並んでいたものを、他の場所でB・C・Aのように並べない。 |
| 宣言をブロックにまとめる | メソッド内を論理的なグループに分けてあげる。(例えば、コンストラクタ、デストラクタはグループ化して配置する) |
| コードを段落に分割する | 文章と同じように、コードも段落に分割する。改行を使って大きなブロックを論理的な『段落』に分ける |
第五章 コメントすべきことを知る
ここでのポイントは、コメントの目的はコードの意図を読み手に理解してもらうという点。コードの意図を理解してもらうために、本では下記観点が紹介されていた。
| 観点 | 説明 |
|---|---|
| 不要なコメントを知る | ・コードからすぐわかることを書かない ・ひどい名前はコメントではなく名前を変える (自己文書化した名前が望ましい) |
| 自分の考えを残す | ・なぜ他のやり方ではなくこうしているかの大切な考えを残す ・コードの品質や状態がわかるようにする ・定数を決めたときの理由を残す |
| 読み手の立場になって考える | ・『え?』と思われそうなところにコメントを残す (『普通は〇〇なのに、なんで△△?』と思われる場所) ・ハマりそうな罠を示す (当該コードを使う前に気づけるようにする) ・『全体像』がわかる情報をつける ・関数内部の塊を要約する (塊を関数に分割できるならそっちのが望ましい) |
自分の考えを残す観点の『コードの品質や状態がわかるようにする』は、プログラマがよく使う記法があって、それを用いてわかるようにするらしい。
| 記法 | 典型的な意味 |
|---|---|
| TODO: | 後で手をつける |
| FIXME: | 既知の不具合があるコード |
| HACK: | あまりキレイじゃない解決策 |
| XXX: | 危険!大きな問題がある |
上記のように、色々書いたが、自分の考えを上手にコメントするというのもなかなかハードルが高い😅(ライターズブロックというらしい)。 そうは言っても書き始めないと何もならないので、本ではコメントの作業を3つの手順に分解し、上手なコメントを意識した方法で書き出すことを推奨していた。
- 頭の中にあるコメントをとにかく書きだす
- コメントを読んで(どちらかといえば)改善が必要なものを見つける
- 改善する
また、この章を通して、すごく印象的だった言葉は下記。 > コメントを読むとその分だけコードを読む時間がなくなる。コメントは画面を占領してしまう。言い換えれば、コメントにはそれだけの価値を持たせるべき
それほどのことを考えてコメントをつけていなかったので、今後はコメントの価値ということも頭に入れてコードを書いていきたい。
第六章 コメントは正確で簡潔に
ここでのポイントは、コメントは簡潔で多くの情報を詰め込むように意識するという点。そのためのポイントを、本では下記が紹介されていた。
| ポイント | 説明 |
|---|---|
| 代名詞を避ける | 読み手によって何を指しているかわからなくなる可能性があるから、 代名詞を使わず明確に書く |
| シンプルに書く | コードの振る舞いを単純かつ直接的に書く 例えば、『~によって優先度を変える』でなく『~でなければ優先度を高くする』 |
| 正確に書く | コードの動作を正確に示すようなコメントを残す 例えば、『改行の数を数える』でなく『'\n'の数を数える』 |
| 実例を書く | rubyの公式のメソッドの説明で見るような実例を載せる。p "foo".rjust(10) # => " foo" |
| コードの意図を書く | 動作を高レベルに説明し、プログラムの意図を正しく伝える。 例えば、『逆順にイテレート』ではなく『値段の高い順に表示』 |
| 名前付き引数を使う | 引数のみだと動作が分かりにくい時、名前付き引数で分かりやすくする。C++とかならインランインコメントを用いる |
| 情報密度の高い言葉を使う | パターンやイディオムを説明するための言葉や表現(専門用語的なもの)で簡潔に示す。 |
第二部:ループとロジックの単純化
第七章 制御フローを読みやすくする
ここでのポイントは、制御フローの構成を考えて、より読みやすくなる方法を覚えておくという点。これまでのプログラマたちの経験から、ある程度『読みやすいコードとはなんぞや?』という観点があり、本では下記が紹介されていた。
| 観点 | 説明 |
|---|---|
| 条件式の引数の並び順 | 変化する『調査対象』の式を左側、変化しない『比較対象』の式を右側にする 例えば、"現在気温" > "クーラーON閾値温度" |
| if/elseの並び順 | 肯定系で書く。単純、目立つ、関心を引くような条件を先に書く。 理由は目立つコードで集中を欠けせないため。 |
| 三項演算子、do-while、gotoは使い所を考える | コードが読みにくくなることが多いので、基本的には使わずに、代替となるもので対応する。 |
| 関数から早く返す | 早めに返すと、ネストを削除したりコードをクリーンにできる。ガード節(関数上部で単純な条件を先に処理するもの)が便利。 |
| ネストを浅くする | ネストが深い場合、条件を覚えておく必要があり、コード読むのが大変になるので、基本的に浅い方がいい。浅くする方法としては、早めに返したり、ループではcontinueを使って処理を飛ばしてしまう。 |
この中で印象的だったのは、『関数から早く返す』という観点。現職ではretunrnは一つということが推奨されていたので、『へー😲』となった。確かに、早く返してしまえばそれ以降は読む必要がなくなるので、読みやすいコードになる気がした。
第八章 巨大な式を分割する
ここでのポイントは、巨大な式は分割して、読み手がコードを飲み込みやすくするという点。コードの式が長いと理解が難しくなるため、コードを飲み込みやすくするための処理や分割方法が紹介されていた。
| ポイント | 説明 |
|---|---|
| 説明変数 | 式を分割するために、式を表す変数を使う。 |
| 要約変数 | 大きなコードの塊を小さな名前に置き換える。 それにより管理や把握を簡単にできる。 |
| ド・モルガンの法則を使う | 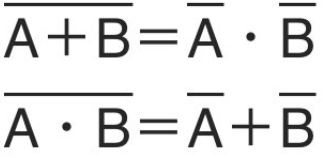 |
| 違う手法を考える | 複雑なロジックになってしまった場合は、全く異なる手法で考えてみる。例えば、問題を否定したり、反対のことを考えてみる。 |
第九章 変数と読みやすさ
ここでのポイントは、変数を適当に使うと理解しにくくなるという点。理解しにくくなるような使い方は下記のようなもの。
- 変数をやたらめったら使う
8章では、説明変数や要約変数を用いることで、コードが読みやすくなることを学んだけど、不要な変数が使われていると変数の数が大きくなって、理解しにくくなってしまう。 - スコープの大きい変数を利用する
スコープが大きいとスコープを把握する時間が長くなる。 - 変数を頻繁に変更する
現在の値を把握するのが難しくなる。
上記のような理解しにくくなるような方法を知り、それを避けることを本章で学んだ。
| 観点 | ポイント |
|---|---|
| 不要な変数を削除する | ・役に立たない一時変数 (複雑な式を分割していない、不明確、重複コードの削除でない) ・中間結果 (中間結果を保持するだけの変数) ・制御フロー変数 (データではなくプログラムの実行を制御するだけの変数) |
| 大きなスコープを避ける | ・グローバル変数 ・大きなファイル、クラス、関数 ・見えなくても良い場所で見えてしまう変数 |
| 変数は一度だけ書き込む | ・変数を操作する場所は少ない方が良い (操作する場所が多いと現在値の把握が難しくなる) |
第三部:コードの再編成
第二部では、コードを読みやすくするためにプログラムの構造を少しだけ変更する技法を学んだ。第三部では、コードを大きく変更する技法を学ぶ。学ぶ内容は3種類。 * プログラムの主目的と関係のない『無関係の下位問題』を抽出する * コードを再編成して、1度に1つのことをやるようにする * 最初にコードを言葉で説明する。その説明を基にきれいな解決策を作る。
第十章 無関係の下位問題を抽出する
ここでのポイントは、プロジェクト固有のコードから汎用コードを分離するという点。無関係の下位問題とは、ある関数やコードブロックの各コード行が処理する内容が、その関数の責務(目標)に対して直接的な効果がない部分のコードのことを指す。ある関数の責務に対して無関係の下位の問題を解決することから、『無関係の下位問題』と言われている。
無関係の下位問題の抽出については、下記の流れで抽出を行うと良いらしい。
- 関数やコードブロックの内容から、『ここの責務は何か?』を考える
- 当該部分の中で、責務に直接関係しない部分を考える
- 無関係の下位問題を解決しているコードがある程度あれば、それを抽出して別の関数にする
抽出する時の観点を下記にまとめる。
| 観点 | 説明 |
|---|---|
| 再利用可能な処理 | 無関係の下位問題は自己完結しているので、どの関数から呼ばれても処理を実行できる。 |
| ユーティリティコード | このライブラリに『こんな関数があればなぁ』と思うときに、自身で複数のプロジェクトで使えるユーティリティコードとして実装する |
無関係の下位問題を解決していくと汎用コードがたくさん出来てくる。汎用コードはプロジェクトから切り離されているため、コード開発もテストも理解も楽になる。 ただし、やりすぎも良くない😅。小さな関数を作りすぎると、あちこちのコードを飛び回ることになるため、逆に読みにくくなる。
第十一章 一度に一つのことを
ここでのポイントは、関数の論理的な『段落』を作るという点。関数の中で一つの処理という意味もあるし、関数の中でもコードを小さく構成し、論理的な区分に分けてあげるとわかりやすくなる。それを図示したものが下記の図。下図の左側の方法では、一つの関数の中でいろんなことをちょっとずつコードで実施している。右側の方法ではタスクの種類によってまとめて実施している。理解しやすいのは、文章を読むのと同じで論理的な区分を設けてコードを書く右側となる。
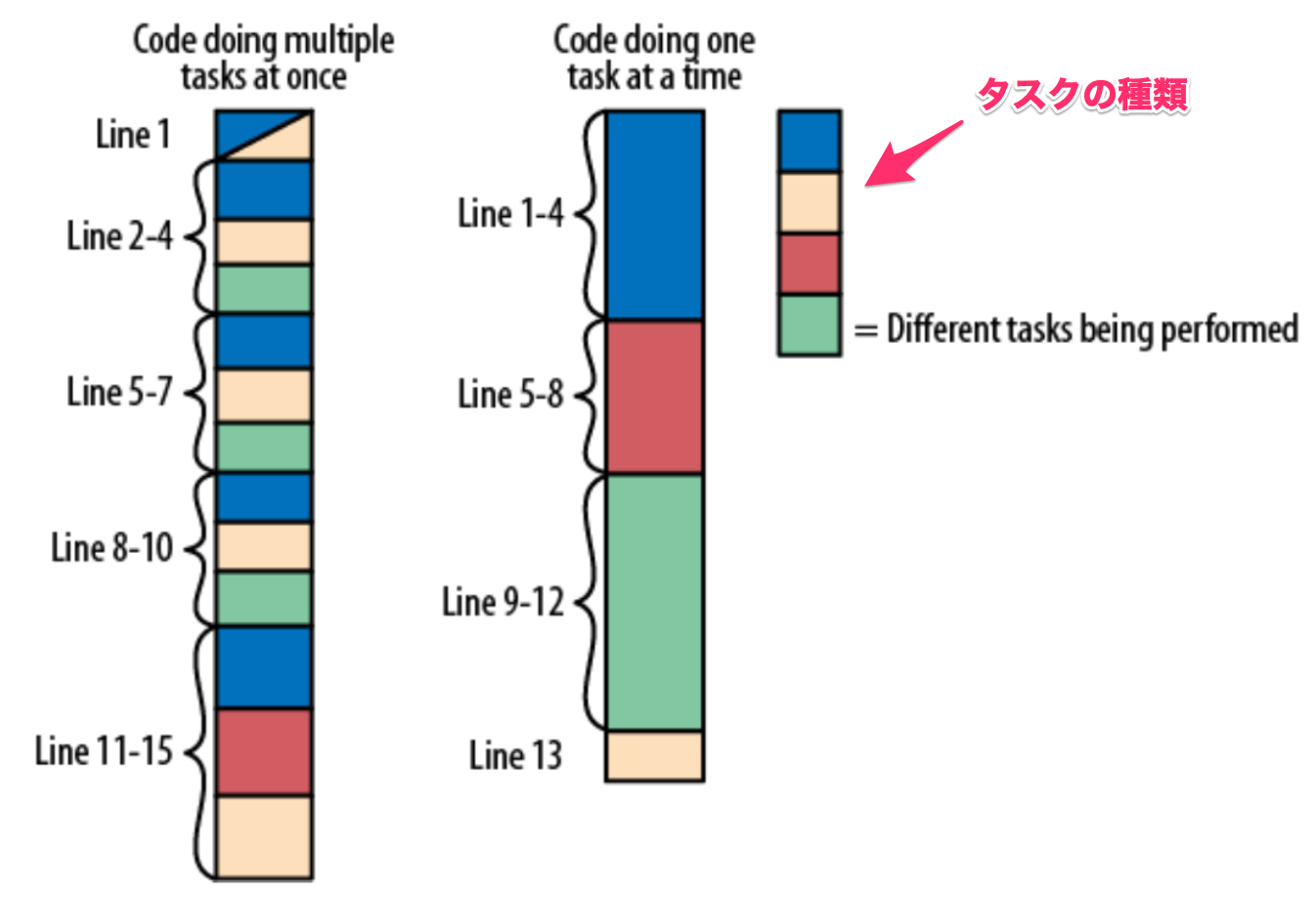
では、どうやって『一度に1つのタスクをする』ようにするかというと、下記の手順が紹介されていた。
- コードが行っているタスク(細かなものから抽象的なものまで)を全て列挙
- タスクをできるだけ異なる関数に分割する。少なくとも異なる領域に分割する
具体例としては、下記のようなもの。

第十二章 コードに想いを込める
ここでのポイントは、プログラムを書く前にプログラムを簡単な言葉で説明するという点。
自分の考えを人に伝えるときには、誰でもわかるように『簡単な言葉』かつ端的に伝えることが日常生活でも重要だけど、それはコードにも当てはまる。なので、一度自分の言葉でコードを簡単に言語化するのが重要ということ。
言語化することで得られる旨味は下記。 * 説明で使用した単語やフレーズで分割すべき下位問題がわかるようになる * 人の思考を重視したコードになることで、人が理解しやすいコードになる
じゃあ、実際にどのようにしてコードを書いていくか?ってことは、本では下記が紹介されている。 1. コードの動作を簡単な言葉で説明する。(同僚がわかるレベル) 2. その説明で使用しているキーワードやフレーズに注目する 3. その説明に合わせてコードを書く
その他にも、重要な点が紹介されていた。
* ライブラリを上手に使う
簡単なコードを書くために欠かせない。ライブラリを使うことで、コードを短く直感的に書ける。よって、ライブラリが何を提供するかを知っておくことがとても重要。
確かにRuby公式を学んでいるときにもサラッとメソッドに目を通しておく良いと推奨されていたが、ここに紐づくんだお感じた。
印象的だった言葉は下記のもので、胸が痛いなと感じた😅
問題や設計をうまく言葉にできないのであれば、何か見落としているか、詳細が明確になっていないということ
第十三章 短いコードを書く
ここでのポイントは、できるだけコードを書かないようにするという点。新しいコードを書くということは、テストや文書や保守が必要になるし、コードを理解してもらう量が増えることになる。なので、根本的にコードを書かない(短いコード)のが良いと言える。 じゃあ、新しいコードを書かないようにするにはどうするか?ってことだけ、本では下記が紹介されていた。
| ポイント | 説明 |
|---|---|
| 機能を過剰にしない | 要求を詳しく調べて、要求のコアを見つけ、そこに対して最も簡単に問題を解決できる方法を考える |
| コードを小さく保つ | コードを小さく軽量に維持するために下記を意識する ・汎用的な『ユーティリティ』コードを作って、重複を削除 ・未使用のコードを削除 ・プロジェクトをサブプロジェクトに分割 |
| ライブラリに親しむ | ライブラリを使うことで、時間とコードが節約できる。そのために、ライブラリの機能についてあらかじめ目を通して、何ができるかを知っておくことが大切。 |
| CLIも使う | コードがダメなら、Unixのコマンドラインなどの方法も検討する |
リーダブルコード 第四部:選抜テーマ
第四部では、これまでに学んできたコードを理解しやすくするための技法を、実際に適応する例が紹介されている。リーダブルなコードにしていく際にどういう流れで適応していくかを思い出すときに読むといいと思った。
第十四章 テストと読みやすさ
ここでのポイントは、テストコードも読みやすさが大切という点。テストが読みやすければ、テストを書きやすいし、他の人もテストを追加しやすい状態になる。また、テストしやすいコードというのは、コードの設計自体も改善されているものになりやすい。
じゃあ、読みやすいテストコードにするために何をしないといけないかというと、下記を意識すると良いと記述されていた。
- テストのトップレベルは簡潔にする
入出力のテストは、一行のコードで記述できているとベター - エラーメッセージを読みやすくする
テストが失敗したときにバグや修正がわかるようなエラーメッセージが出力されるようにする。そのために、テストに役立つライブラリやフレームワークを知っておく必要がある。いいのがなければ手作りのアサートを作るなどして、役立つエラーメッセージを作る。 - テストに有効な最も単純な入力値を使う
入力値には、コードを完全にテストする最も単純な入力値の組み合わせにする必要がある。複雑な値や目を引く値で入力を作ってしまうと、何をテストしたいかがぼやけてしまうため。また、1つの機能に複数の小さなテストを用意した方が、簡単・効果的・読みやすいテストになりやすい。 - テストの機能に名前をつける
テスト関数に説明的な名前をつけて、何をテストしているかを明らかにする。例えば、Test1()ではなく、Test1_<関数名>_<状況>のような名前。テスト自体は他のコードから呼び出されるものでないので、名前が長くなってしまったも問題なし!
テストは重要だけれど、テストを意識しすぎてやりすぎてはダメ。以下に注意とのことだった。
- テストのために、テスト対象のコードにゴミを入れない
テストを読みやすくするために、テスト対象を読みにくくするような対応はしてはダメ。意識するのは、テスト対象は単純で疎結合、テストは読み書きしやすく。 - カバレッジ100%にこだわる 重要度に応じて、カバレッジを考える。どうでもいいような機能のところに力を入れすぎない。
- 目的を見失わない
テストはあくまでもプロジェクトの一部。ある種の儀式的な位置付けとして、多大な時間かけてやるようになってきたら、何かずれていると感じて本当にやりたかったことができているかを見直す。
第十五章 『分/時間カウンタ』を設計・実装する
第十四章よりもさらに実務的な解説の章であった。内容自体は、どうリーダブルなコードにしていくかの流れを実務例として紹介している感じのものなので、現職であったり、プラクティスを進めるときに参考にすればいいかなと思った。